Data-driven modeling of collaboration networks: A cross-domain analysis
- Mario Vincenzo Tomasello , Giacomo Vaccario , Frank Schweitzer
- February 8, 2021 Official Link
The analysis shows that collaboration networks from two different domains, economics and science, share common structural features. A data-driven modeling approach was used to calibrate agent-based models for each domain, which were then validated by reproducing network features not used for calibration. The results indicate that newcomers in R&D collaborations prefer links with established agents, while newcomers in co-authorship relations prefer links with other newcomers. This sheds new light on the role of endogenous and exogenous factors in network formation.
In R&D collaborations newcomers prefer links with established agents, while in co-authorship relations newcomers prefer links with other newcomers.
Why This Matters for Scientists
You may want to use this data-driven modeling approach in your research to understand collaboration patterns and reproduce network features not used for calibration.
Quick Technical Overview
The agent-based model was developed in the context of R&D collaborations and assumes simple rules of link formation that are followed by agents with certain probabilities. The model was then extended to and validated in other domains, including co-authorship networks.
This investigation can also provide some evidence to our initial conjecture whether there may be a unified modeling approach for collaboration networks in different domains.
Summary for Policy Makers
The results of this study have implications for policies and funding schemes that aim to allocate resources efficiently and foster innovation. The data-driven modeling approach can help to understand collaboration patterns and identify similarities and differences between different domains. This can inform the design of more effective collaboration strategies.
By understanding how we collaborate, we can re-design funding schemes and policies to allocate resources efficiently, and better foster innovation.
Disclaimer
The above summaries were generated with the assistance of an AI system.
Abstract
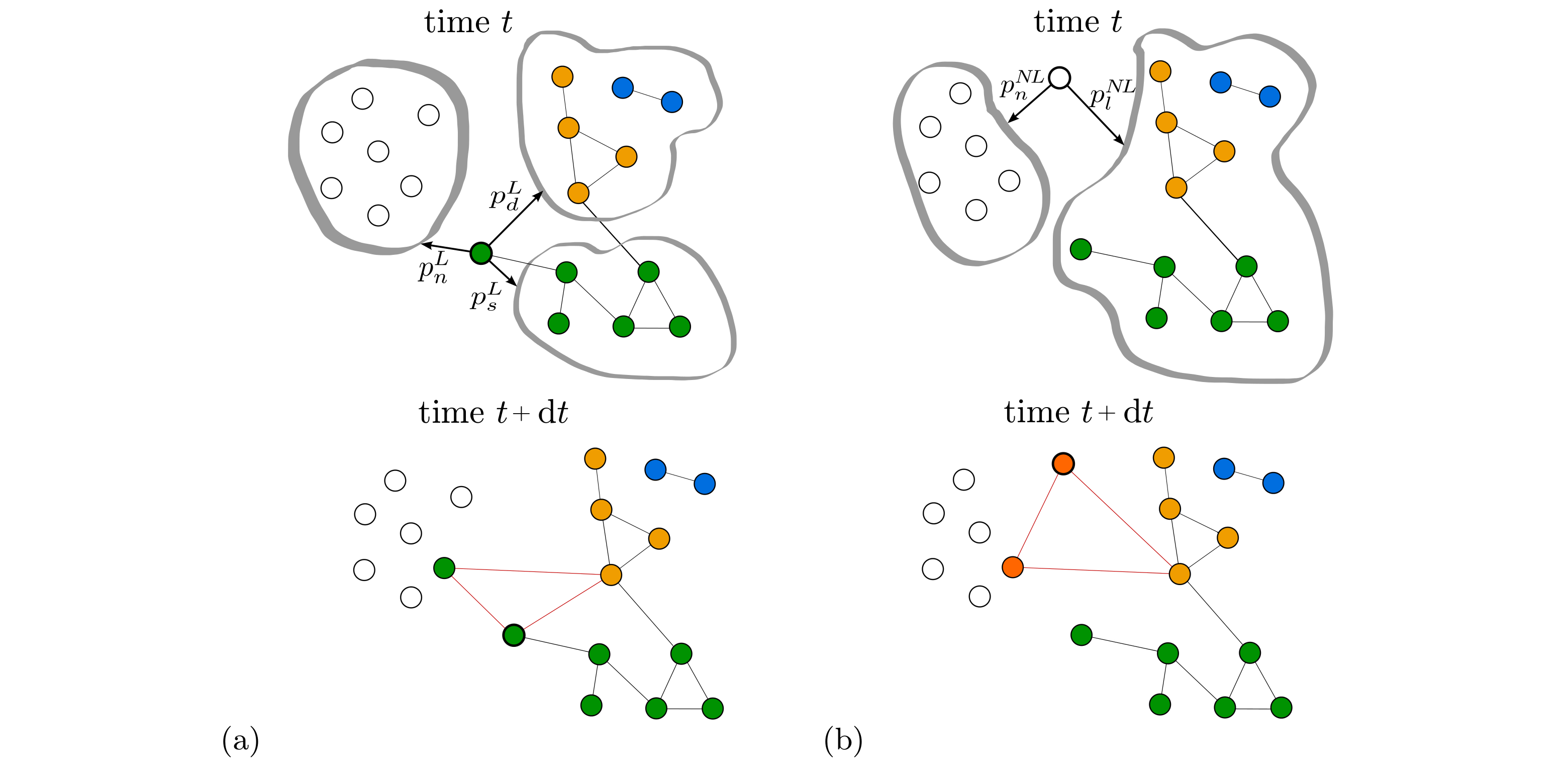
We analyze large-scale data sets about collaborations from two different domains: economics, specifically 22.000 R&D alliances between 14.500 firms, and science, specifically 300.000 co-authorship relations between 95.000 scientists. Considering the different domains of the data sets, we address two questions: (a) to what extent do the collaboration networks reconstructed from the data share common structural features, and (b) can their structure be reproduced by the same agent-based model. In our data-driven modeling approach we use aggregated network data to calibrate the probabilities at which agents establish collaborations with either newcomers or established agents. The model is then validated by its ability to reproduce network features not used for calibration, including distributions of degrees, path lengths, local clustering coefficients and sizes of disconnected components. Emphasis is put on comparing domains, but also sub-domains (economic sectors, scientific specializations). Interpreting the link probabilities as strategies for link formation, we find that in R&D collaborations newcomers prefer links with established agents, while in co-authorship relations newcomers prefer links with other newcomers. Our results shed new light on the long-standing question about the role of endogenous and exogenous factors (i.e., different information available to the initiator of a collaboration) in network formation.